
Guidance, Navigation, and Control
The functions of Guidance, Navigation, and Control are vital to all forms of air and space flight. The Space History collections in this area attempt to reflect that significance and illustrate the breadth of the topic.
In practice, these three functions blend into one another, and artifacts from this collection often perform multiple duties. For this collection, "guidance" shall refer to controlling a vehicle during acceleration or deceleration, mainly during the powered phase of flight, i.e. to align the thrust vector of a rocket or jet engine to coincide with (or deviate slightly from) the vehicle's center of mass, or to use aerodynamic controls such as fins to aim the vehicle properly during its flight. Guided missiles, which are powered for most of their flight, require continuous guidance (hence the name), but in a typical space mission, a rocket burns for only a fraction of the total time of the mission and would require guidance for only that short period of time. Once the rocket engines shut off, there follows the function of "navigation," which is to get from one position in space to another. In contrast to navigation at sea or in the air, space navigation typically consists of long periods of coasting with periodic corrections. Finally, "control" is defined as orienting the spacecraft in its rotational axes to perform its various operations, such as pointing a telescope, orienting an antenna toward Earth, preparing the vehicle for a rocket burn, etc. Again in contrast to aircraft and ships, in the absence of an atmosphere, a spacecraft may be oriented in any direction, but it is usually not desirable to allow it to tumble with no control.
"Control" is also used in another context, namely the management of a mission from the ground (e.g. NASA's "Mission Control" in Houston). Passenger aircraft fly with periodic communication with air traffic controllers on the ground, but in general, they fly with a great deal of autonomy. In contrast, spacecraft that carry a human crew are intensively managed from the ground, where controllers monitor the vehicle's performance, ensure the safety of the crew, and manage the crew's schedule and operations. Robotic spacecraft may require less control, but during critical phases of their missions, they are also intensively controlled from Earth. The National Air and Space Museum's collections in this area attempt to show the breadth and depth of this topic by a judicious selection of artifacts.
Image-Based Optimal Powered Descent Guidance via Deep Recurrent Imitation Learning
Luca Ghilardi, Andrea D'Ambrosio, Andrea Scorsoglio, Roberto Furfaro, Richard Linares, Fabio Curti
Future missions to the Moon and Mars will require autonomous landers/rovers to perform successful landing maneuvers. In order to accomplish this task, reliable, fast and autonomous Guidance, Navigation, and Control (GNC) algorithms are necessary. In recent years, the strong capabilities of modern hardware have allowed employing deep learning models for space applications. In this work, SSEL presents an image-based powered descent guidance via deep learning to control the command acceleration along the three axes. In particular, a hybrid architecture, composed of a Convolutional Neural Network and a Long Short Term Memory (CNN-LSTM), is trained using, as inputs, sequences of images taken during the descent. Hence, the whole neural network maps the sequences of images into the values of the command acceleration. The images are generated within a simulated environment with physically based ray-tracing capabilities.
SSEL proposes a new approach based on deep learning that integrates guidance, navigation, and control functions, providing an end-to-end solution to the lunar landing problem. More specifically, by implementing a class of CNNs and Recurrent Neural Networks (RNNs) capable of learning the underlying functional relationship between a sequence of optical images taking during the descent and the thrust action. The system learns in a simulated environment where optimal trajectories are computed via known optimization methods, and spacecraft position and velocity are correlated directly through ray-tracing simulation to the related optical image taken by the on-board camera.
Methodology
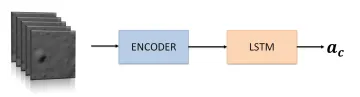
SSEL approach aims to create a deep neural network (DNN) that can allow the spacecraft to autonomously land on the Moon surface with an energy optimal-based trajectory, given random initial conditions. The goal is to create a logical connection between the motion of the terrain features in the camera frame and the control action to achieve the desired trajectory. To achieve it, we train a hybrid neural network in a supervised fashion, which means that both data and the ground truth labels are the inputs of the models. In this work, the data are sequences of images frames taken by the lander camera, supposed to always point towards the surface (Figure on the right). The respective labels are the accelerations correlated to the last frame of the sequence. Indeed, these accelerations are previously generated via ZEM/ZEV guidance.

Data-set
The first step to create the data-set is to generate ZEM/ZEV trajectories for both training and test sets. These trajectories are obtained by considering the common dynamics equations of a landing on a flat surface of a large planetary body without atmosphere. Within this framework, only the translational dynamics are taken into account, while the attitude dynamics are supposed to be independent and treated separately. However, rotational dynamics are not considered in this work. In the machine learning framework, it is well known that a generalized training-set is fundamental to ensure an unbiased estimation. For that reason, a set of trajectories has been created with an initial position varying randomly inside a sphere of radius 300 m and a final position varying within a circle of radius 100 m on the surface. For what concerns the initial velocity, it is supposed to randomly change within a sphere, as well. Besides, thanks to the ray-tracing software Blender, we import a Digital Terrain Model (DTM) from the Lunar Reconnaissance Orbiter Camera (LROC) website. The region chosen for the landing is the Apollo 16 landing site (Figure on the left). The trajectories are correctly scaled to the Blender’s framework to be compliant with the terrain model scale.
In this work, we use Cycles renders, an open-source physically based production rendering engine developed by the Blender project, to generate a grey-scale image at each position of the trajectories. The Blender option ”adaptive subdivision” is used to increase the number of polygons of the DTM as the camera gets closer to the surface to emulate the reality where new features appear when the camera approaches the terrain.
Once the train and test-set are ready, the data must be prepared before being fed into the model. We create a 5D tensor with the following dimensions: batch-size, number of frames, number of channels, image height, image width. The number of frames is the number of consecutive images that will be processed in one iteration in the Long Short Term Memory (LSTM) cell. This number has a significant impact on the quality of temporary information extracted by the LSTM. On the other hand, it also affects the number of parameters in the model. Therefore, a trade-off should be done to achieve a good compromise between the performances and the computational time.
Safe Lunar Landing via Images:
A Reinforcement Meta-Learning Application to Autonomous Hazard Avoidance and Landing
Andrea Scorsoglio, Andrea D'Ambrosio, Luca Ghilardi, Roberto Furfaro, Brian Gaudet, Richard Linares, Fabio Curti
Future missions to the Moon and Mars will require advanced Guidance, Navigation, and Control (GNC) algorithms for the powered descent phase. GNC tasks are generally performed by independent modules. In this work, reinforcement metalearning and hazard detection and avoidance are embedded into a single system to derive the optimal thrust command for a safe lunar pinpoint landing using sequences of images and radar altimeter data as inputs. In particular, we incorporate autonomous hazard detection and avoidance and real-time GNC, which are essential for a successful landing. The former are achieved using a machine learning model trained in a supervised fashion to recognize hazardous areas in the camera field of view and selecting a safe point accordingly. Then, within the reinforcement meta-learning framework, this information is used by the agent to learn how to optimally behave in this simulated environment and land safely.
In this work, SSEL proposes a new approach based on deep learning that integrates guidance and navigation functions providing a complete solution to the lunar landing problem that integrates an image-based navigation to an intelligent guidance. Hazard avoidance and detection are also considered to autonomously detect safe landing sites and they are embedded in the global framework by using a CNN trained via supervised fashion. More specifically, we design a simulation environment that is able to integrate the dynamics of the system and simulate image acquisition from on-board cameras. This is achieved by interfacing the simulator in Python with a ray tracer (i.e. Blender) that generates accurate images using lunar digital terrain models (DTM) and a physically-based rendering engine. The images are then used to update a policy in real time using reinforcement learning. The hazard detection and avoidance are also taken into account in the definition of the reward function. We take advantage of the latest discoveries in CNN and Recurrent Neural Networks (RNN) for image processing and Proximal Policy Optimization (PPO) to design our agent and learn the optimal policy for soft landing.
Methodology
The proposed approach relies on a combination of deep learning, computational optimal control and hazard detection, supported by the ability to generate simulated images of the lunar surface. The overall goal is to teach a spacecraft to autonomously execute lunar landing in an unsupervised manner by processing a sequence of optical images taken by the spacecraft on-board camera and data from a radar altimeter and produce an adequate thrust command. The overall approach is to train a set of CNNs and RNNs to map a sequence of optical images into continuous thrust actions ut. This is achieved using a simulation pipeline that integrates the equations of motion to simulate the dynamics and generates sensor data simultaneously in near real-time. The dynamical model employed is the classical landing model considered for a flat surface of a planetary body without atmosphere. The agent’s knowledge of the environment is limited to the optical image, vertical position and velocity and a feedback reward signal based on the actions it takes. For what concerns the hazard detection and avoidance, we use a special convolutional neural network, called Unet, that performs semantic segmentation. This has been trained in a supervised manner to separate hazardous and safe areas in an image of the surface of the Moon. The safest spot is selected according to its distance from hazardous areas. The reward is then calculated according to the distance of this point from the center of the frame and the vertical velocity to successfully perform a soft landing. Reinforcement learning algorithms like PPO then use this experience to learn the optimal policy. The Figure below shows the overall framework where it is clearly shown how the dynamic simulator, the raytracer and the hazard detection model work together with the RL algorithm in closed loop.
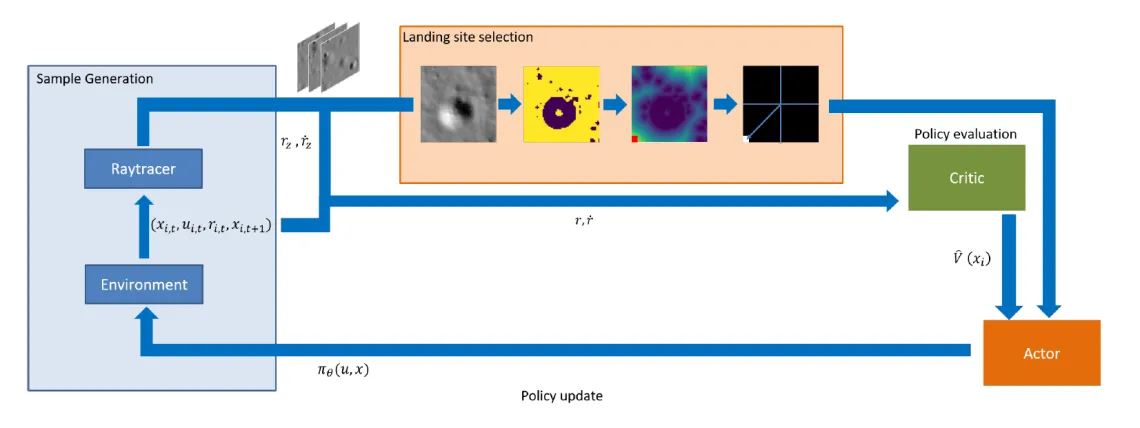
Raytracer
Raytracing is the state of the art in the field of realistic rendering. It has been used extensively for producing realistic and physically accurate environment renders. It achieves near photo-realistic quality by modeling the interaction of photons emitted by a light source with the objects in the scene and the camera. In this case, we use Cycles renderer, an open source physically based production rendering engine developed by the Blender project. This, not only has shown to work extremely well in many applications but it also has some advantages over other rendering engines (i.e. POVray). The fact that it runs in Blender makes it easy to integrate the renderer in the machine learning pipeline. Indeed, Blender natively support Python scripting which makes it easy to be interfaced with Python where the environment is simulated and learning takes place. It also supports multi GPU rendering using Nvidia CUDA APIs, which is important to speed up the sample generation time and learning. It should be noted in fact that PPO is an online algorithm that has to be fed continuously with new batches of samples for a successful learning.
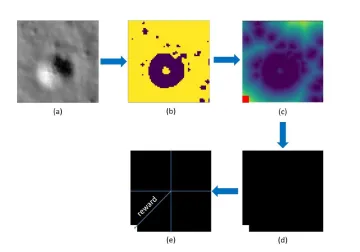
Hazard detection and avoidance
In order to select a safe zone for landing, a method for hazard identification and characterization must be developed. In this paper, we used a particular kind of neural network that is able to recognize and label different areas of an image based on a ground truth mask. Specifically, the network is comprised of an encoder and a decoder. The encoder extracts information from the input image (Fig. a) by applying a sequence of convolutional filters and reducing the image size. The decoder then upscales that information back to create a labelled image with the same size as the input. The output of the net is a labelled image in which safe and unsafe areas are identified with different colours (Fig. b). The algorithm then calculates the minimum distance from the closest hazardous pixel in the image matrix. The safest spot will then be the pixel with the biggest among the minimum computed distances (Fig. c). This information is then used to create an additional image that is black everywhere except where the safe landing pixel resides (Fig. d). This image, here referred to as the target image (Fig. e), is then fed to the guidance algorithm. The white pixel, called landing pixel, represents the current landing spot to track (the landing site can change if a new safer spot is found): its distance from the centre of the camera is used as a term of the reward to make the agent learn how to land in a correct landing site. One can note that keeping the landing pixel in the centre of the field of view, always considered to point the nadir, means that a vertical landing is occurring. This is important especially during the last phase of a landing trajectory.
Our Publications
- Furfaro, R., Scorsoglio, A., Linares, R., & Massari, M. (2020). Adaptive generalized ZEM-ZEV feedback guidance for planetary landing via a deep reinforcement learning approach. Acta Astronautica. DOI: http://dx.doi.org/10.1016/j.actaastro.2020.02.051
- Furfaro, R., & Mortari, D. (2020). Least-squares solution of a class of optimal space guidance problems via theory of connections. Acta Astronautica, 168, 92-103. DOI: https://doi.org/10.1016/j.actaastro.2019.05.050
- Holt, H., Armellin, R., Scorsoglio, A., & Furfaro, R. (2020). Low-Thrust Trajectory Design Using Closed-Loop Feedback-Driven Control Laws and State-Dependent Parameters. In AIAA Scitech 2020 Forum (p. 1694). DOI: https://doi.org/10.2514/6.2020-1694
- Scorsoglio, A., Furfaro, R., Linares, R., & Gaudet, B. (2020). Image-based Deep Reinforcement Learning for Autonomous Lunar Landing. In AIAA Scitech 2020 Forum (p. 1910). DOI: http://dx.doi.org/10.2514/6.2020-1910
- Johnston, H., Schiassi, E., Furfaro, R., & Mortari, D. (2020). Fuel-Efficient Powered Descent Guidance on Large Planetary Bodies via Theory of Functional Connections. arXiv preprint arXiv:2001.03572. PDF
- Scorsoglio, A., Furfaro, R., Linares, R., & Massari, M. (2019). Actor-critic reinforcement learning approach to relative motion guidance in near-rectilinear orbit. In 29th AAS/AIAA Space Flight Mechanics Meeting (pp. 1-20). PDF
- Drozd K., Furfaro R., & Mortari D. (2019). Constrained Energy-Optimal Guidance in Relative Motion via Theory of Functional Connections and Rapidly-Explored Random Trees. Conference: 2019 AAS/AIAA Astrodynamics Specialist Conference. Portland, ME, USA. PDF
- Schiassi E., Furfaro R., Johnston H., & Mortari D. (2019). Fuel-efficient Powered Descent Guidance on Planetary Bodies via Theory of Functional Connection 1: Solution of the Equations of Motion, AAS 19-718, AAS/AIAA Astrodynamics Specialist Conference, Portland, ME. PDF
- Scorsoglio, A., & Furfaro, R. (2019), ELM-based Actor-Critic Approach to Lyapunov Vector Fields Relative Motion Guidance in Near-Rectilinear Orbits. Conference: 2019 AAS/AIAA Astrodynamics Specialist Conference. Portland, ME, USA. PDF
- Drozd, K. M., Furfaro, R., & Topputo, F. (2018). Application of ZEM/ZEV guidance for closed-loop transfer in the Earth-Moon System. In 2018 Space Flight Mechanics Meeting (p. 0958). DOI: http://dx.doi.org/10.2514/6.2018-0958.c1
- Jiang, X., Furfaro, R., & Li, S. (2018). Integrated guidance for mars entry and powered descent using reinforcement learning and gauss pseudospectral method. In 4th IAA Conference on Dynamics and Control of Space Systems, DYCOSS 2018 (pp. 761-774). Univelt Inc.. DOI: https://doi.org/10.1016/j.actaastro.2018.12.033
- Furfaro, R., Bloise, I., Orlandelli, M., Di Lizia, P., Topputo, F., & Linares, R. (2018). Deep learning for autonomous lunar landing. In 2018 AAS/AIAA Astrodynamics Specialist Conference (pp. 1-22). PDF
- Campbell, T., Furfaro, R., Linares, R., & Gaylor, D. (2017, January). A deep learning approach for optical autonomous planetary relative terrain navigation. In 27th AAS/AIAA Space Flight Mechanics Meeting, 2017 (pp. 3293-3302). Univelt Inc. PDF